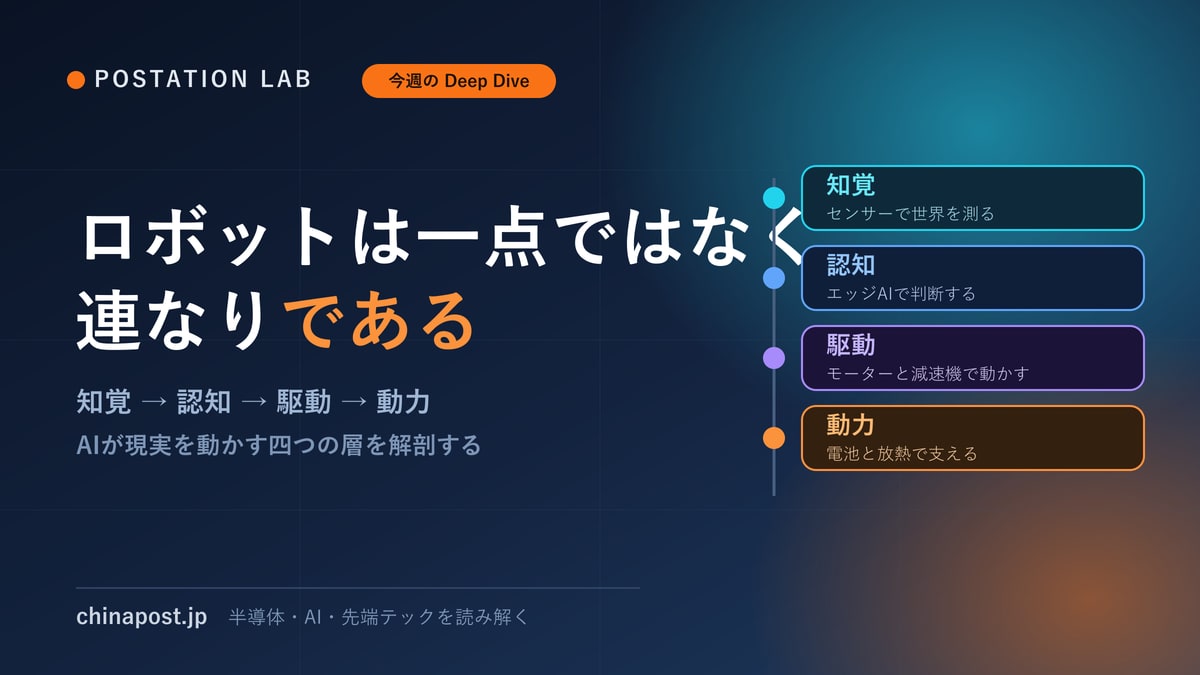
ロボットや自動運転を動かす物理AIを、世界モデル・VLA・シミュレーション・強化学習・アクチュエーターまで論文と型番で解剖。Cosmos、GR00T、Genie、π0の内部構造と、仮想と現実を隔てるsim-to-realの溝を学術レポートの精度で読み解く。
言語モデルが文章を、画像モデルが絵を生成する段階を超えて、人工知能が物体を掴み、躓きを立て直し、車線変更の可否を判断する領域へ踏み込もうとしている。エヌビディアのジェンスン・フアンが2024年以降に広めた「物理AI(Physical AI)」という呼称は、現実の物理法則を内部に学習し、世界がこの先どう動くかを予測したうえで身体を動かす知能を指す。その核心は派手なデモではなく、ハンス・モラベックが1988年に指摘した逆説——計算機にとって知能検査やチェスは易しく、一歳児の知覚運動能力は難しい——をどう乗り越えるかにある。本稿は、物理AIを構成する世界モデル、視覚・言語・行動モデル、シミュレーション、強化学習、そしてセンサーとアクチュエーターという各層を、論文と型番のレベルまで分解し、産業全体の構造を技術として読み解く。出発点は、人間が頭の中で「こう動けばこうなる」と先回りする能力を、機械にどう持たせるかという問いである。
「物理AI」が指すもの ― 認識する知能から、世界に触れる知能へ
フアンは、人工知能が三つの段階を踏んできたと整理する。画像や音声を識別する「認識型AI」、文章や画像を生み出す「生成AI」、道具を使い計画を立てて動く「エージェント型AI」、そしてその先に来るのが、自ら推論し計画し、現実世界で行動する「物理AI」である。この区分は単なる宣伝文句ではなく、扱うデータの性質が質的に変わることを示している。認識型と生成型がインターネット上に存在する画像・テキスト・動画という「すでに記録された世界」を学ぶのに対し、物理AIは記録の外にある「これから起きる物理現象」を予測しなければならない。
従来のAIと物理AIを分けるのは、扱う対象がデジタル情報か、質量と摩擦と慣性を持つ物体かという一点に尽きる。検索エンジンが誤った答えを返しても画面が書き換わるだけだが、ロボットアームが0.1秒の判断を誤れば部品を破壊し、自動運転車が歩行者の進行方向を読み違えれば人命に関わる。物理AIの本質は、現実世界の認識、次に起きることの予測、行動の決定、そして結果のフィードバックという一連の閉じた循環(クローズドループ)を、不可逆な現実のなかで完結させる点にある。人工知能がロボットに認識・思考・意思決定の「頭脳」を与え、ロボットが人工知能に現実と関わる「身体」を与えるという相互依存が、エンボディドAI(身体性を持つAI)という言葉の中身を成している。
応用先は大きく三つに分かれる。人間向けに設計された環境で働くヒューマノイド、移動という制約付きの身体性を持つ自動運転、そして協働ロボットや自律移動ロボット(AMR)を含む産業用ロボットである。このうち自動運転は最も早く大規模に実装される分野とみられ、ヒューマノイドは最も射程の長い応用領域に位置づけられる。
理論から実装へ ― 物理AIが越えてきた四つの段階
物理AIの来歴は、四つの局面に整理できる。2020年以前は、物理モデリングとAIアルゴリズムの基礎的な融合を大学・研究機関が手がける理論探索の時期で、事業モデルは未確立だった。2020年から2023年にかけて、エヌビディアやグーグル・ディープマインドが参入し、デジタルツインやマルチモーダル認識といった基盤技術が成熟し始めたが、シミュレーション構築費用の高さと、仮想と現実の乖離(後述するsim-to-realの溝)に阻まれ、実証の段階を出なかった。
転機は2024年以降に訪れた。基盤モデルの製品化が加速し、各国の政策支援が重なって実装が進み始めた。2026年に入ると、IDCやガートナーといった調査機関が物理AIを年間の主要技術動向の上位に位置づけ、概念先行の段階から実装の段階へと業界の重心が移った。生成AIが、すでに存在するコンテンツを生成して一般利用者の利用量で広がる経路をたどったのに対し、物理AIは「物理法則とデータ駆動の融合」という、模倣の難しい技術的な参入障壁を軸に据えている点が、発展経路を分けている。
仮想空間で先に失敗する ― 世界モデルという「脳内の物理エンジン」
物理AIの中核にあるのが世界モデル(ワールドモデル)である。これは、ロボットや自動運転車が実際に動く前に、「この行動をとれば次に何が起きるか」を内部のシミュレーターで先回りして試す仕組みを指す。概念の源流は強化学習にあり、ユルゲン・シュミットフーバーらの理論を経て、デヴィッド・ハとシュミットフーバーが2018年に発表した論文「World Models」(NeurIPS 2018)が、外界の生成モデルを脳内に持つという枠組みを明確にした。
その動作原理は、観測した高次元の映像を低次元の潜在表現(latent state)に圧縮し、「現在の状態と行動から次の状態を予測する」遷移モデルを学習する点にある。ダニヤル・ハフナーらのDreamer系列(2019年の「Dream to Control」、2023年のDreamerV3)は、再帰状態空間モデル(RSSM)と呼ばれる潜在動力学モデルを用い、現実環境ではなく潜在空間の中で行動を「想像(imagination)」して方策を最適化する。DreamerV3は、領域ごとの調整なしに、報酬が極端に乏しいマインクラフトのダイヤモンド採掘までこなした。現実で何万回も試行する代わりに「夢の中で」試行できるため、サンプル効率——現実環境との対話回数あたりの学習効率——が桁違いに高まる。これが、現実での試行が高コストかつ危険なロボット制御に世界モデルが効く理由である。
現在の世界モデルの技術的なアプローチは、おおむね三系統に分かれる。
- 動画生成型: 大量の動画から物理的に整合した未来フレームを生成する。オープンAIのSora(2024年)、エヌビディアのCosmos、グーグルのGenieが代表で、世界を「予測可能な動画」として表現する。
- 3次元生成型: NeRF(2020年)や3Dガウシアン・スプラッティング(2023年、SIGGRAPH)で現実空間を立体的に再構成し、視点を自由に変えられる空間そのものを生成する。
- 物理エンジン融合型: 剛体・流体・接触を計算する数値ソルバーと生成モデルを組み合わせ、物理的整合性を担保する。
エヌビディアのCosmos(論文 arXiv:2501.03575)は、この潮流を基盤モデルとして製品化した。2,000万時間の実世界データ(人間の作業、環境、産業、ロボット、運転)を約9,000兆トークンに変換し、H100を1万基・3カ月かけて学習している。拡散モデルと自己回帰モデルの二系統を持ち、自己回帰版の離散トークナイザーは時間方向に8分の1、空間方向に16×16へ圧縮する。物体の衝突や重力といった物理法則を再現できるため、下流のロボットや自動運転モデルに低コストの学習データと検証用の閉じた評価環境を供給する「合成データ工場」として機能する。グーグル・ディープマインドのGenie 3は、文章の指示だけから3次元資産も手作業のプログラミングもなしに、毎秒24フレーム・720pで数分間にわたり一貫性を保つ操作可能な仮想環境を生成し、壁の色を塗り替えても場面転換後に保持される「物体の永続性」が創発的に現れる点で、動画生成を超えて相互作用可能なシミュレーターへ踏み込んでいる。
言葉と映像を関節角度に変換する ― VLA(視覚・言語・行動)モデルの内部
世界モデルが「予測」を担うのに対し、実際に身体を動かす指令を生成するのが視覚・言語・行動モデル(VLA)である。VLAは、カメラ映像と言語による指示を入力に取り、ロボットの関節角度やグリッパーの開閉といった連続値の動作を直接出力する。「言葉の意味を理解する→世界を認識する→作業を完了する」という循環を一つのモデルで閉じる点に新しさがある。
技術的な系譜は、グーグルのRobotics Transformer系列にさかのぼる。RT-1(2022年)が実機データから動作を学び、RT-2(2023年)が視覚言語モデル(VLM)を土台に「動作をもう一つの言語トークンとして表現する」発想を持ち込んだ。続くOpen X-Embodiment計画(論文 arXiv:2310.08864)は、34の研究機関・60のデータセットを束ね、22種類の異なる機体・100万軌跡を超える史上最大の実機データを構築し、RT-2-Xによって「機体をまたぐ(cross-embodiment)」汎化を示した。インターネット規模のテキスト・画像が存在する言語モデルと違い、ロボットの動作データは桁違いに希少であり、この「データの壁」をいかに合成データと機体横断学習で埋めるかが、VLA研究の通奏低音になっている。
動作の表現方法をめぐっては、二つの設計思想が競っている。RT-2のように動作を離散トークンに量子化する方式に対し、フィジカル・インテリジェンスのπ0は、動作を連続的な確率の流れとして扱うフローマッチング(flow matching)を採用し、毎秒50回の滑らかな軌道を生成する。π0は30億パラメータのPaliGemma(VLM)に約3億パラメータの「行動エキスパート」を接ぐ混合エキスパート的な構造をとり、7種類の機体・68作業で洗濯物畳みや食器片付けをこなす。チェン・チーらが2023年に発表したDiffusion Policy(拡散方策)は、動作生成を拡散モデルの逐次的なノイズ除去として定式化し、複数の正解がありうる多峰性の動作分布を素直に扱えることから、12課題平均で従来手法を46.9%上回った。動作を「言語」として吐くか、「連続的な流れ」として描くか——この分岐が、現在のVLA設計の最前線にある。
「速い反射」と「遅い熟慮」 ― 二系統アーキテクチャと推論型VLM
人間が、熱い物に触れて反射的に手を引く一方、将棋の一手をじっくり考えるように、物理AIも速度と熟慮を分業させる二系統(System 1/System 2)構造へ収束しつつある。ダニエル・カーネマンの用語を借りたこの設計では、インターネット規模で学んだVLMが「遅い思考(System 2)」として場面理解と高次の作業計画を担い、視覚運動方策が「速い思考(System 1)」として高頻度の連続制御を担う。
エヌビディアのIsaac GR00T N1(論文 arXiv:2503.14734、GTC 2025発表)は、この構造を20億パラメータのVLAとして実装した。視覚言語モジュールがL40 GPU上で毎秒10回の頻度で場面と指示を解釈し、フローマッチングで学習した拡散トランスフォーマーがその出力に注意を向けながら、機体ごとに異なる状態・動作次元を吸収して運動指令を生成する。学習データは、ウェブ動画・合成軌跡・実機データを積層する「データのピラミッド」方式をとり、付属のデータ生成パイプライン(Teleop→MimicGen→Neural Trajectory→Fine-tune)は、6,500時間相当の人手収集をわずか11時間の計算に圧縮する。フィギュアのHelix(2025年2月)も同じ二系統思想で、インターネット規模のVLM(System 2)と視覚運動方策(System 1)を end-to-end で連携させ、腕・手・胴・頭・指を含むヒューマノイド上半身全体を高頻度で制御する初のVLAとして、約500時間の遠隔操作データと自動生成した言語記述で学習している。「遅い思考」の側では、エヌビディアのCosmos Reasonのような推論型VLMが、入力された動画を物理的常識に照らして推論し、不確実で流動的な環境で先々の行動を能動的に計画する役割を強めている。
シミュレーターが教師になる ― 物理エンジン、レンダリング、合成データ
物理AIの学習を支える最大の生産設備は、現実の工場ではなくシミュレーション基盤である。質の高いシミュレーターを握る者が、基盤モデルの最重要の学習データ源を握る。その能力は三つの要素で決まる。剛体・流体・接触力学・変形を計算する物理エンジン(ソルバー)の精度と速度、出力を現実そっくりの映像へ変換するレンダリングエンジン、そして自然言語の指示から多様な作業場面を自動生成する生成データエンジンである。
最も難所となるのが物理エンジンである。とりわけ接触力学——指が物体に触れた瞬間に働く法線力と摩擦力——は、不連続で、相補性条件(物体は押し合うが引き合わない)とクーロン摩擦を同時に満たす非平滑な問題であり、数値的に解くのが難しい。ディープマインドが開発を引き継いだMuJoCo、エヌビディアのPhysXとIsaac Sim、Omniverse基盤のOpenUSD(ピクサー由来のシーン記述規格)が、この領域の標準を競っている。レンダリング側ではRTXによるレイトレーシング(光線追跡)で物理的に正確な陰影を作り、視覚認識に依存するVLAへ現実に近い映像を供給する。
この方式の急所が、シミュレーションと現実の乖離、いわゆる「sim-to-realの溝(reality gap)」である。仮想空間で完璧に動いた方策が、現実の照明・摩擦・センサー雑音のわずかな違いで破綻する。これを埋める基幹技術が領域ランダム化(domain randomization)で、ジョシュ・トビンらが2017年(IROS)に提唱した。学習時に物体の色・質感・摩擦・質量・照明をわざと乱数で揺さぶり、「現実もまた無数の変種の一つ」とモデルに学ばせることで、未知の現実への転移を成立させる。オープンAIは2019年、片手でルービックキューブを解くロボットハンドDactylを完全に仮想空間だけで訓練し、環境を際限なく難化させる自動領域ランダム化(ADR)で、現実の正確なモデルなしに実機転移を実現した。エヌビディアのCosmosが現実の運転データに合成のエッジケースを足し込めるのも、この合成データ思想の延長にある。
試行錯誤から方策を蒸留する ― 強化学習と模倣学習
VLAやエンドツーエンドの方式が主流になるにつれ、強化学習が学習の中核手法へ復権している。周囲を捉えた動画をエージェントに与え、試行錯誤を繰り返させ、異なる判断が長期にもたらす結果を比較させて、自律的に方策を磨かせる。報酬を最大化するよう方策を更新する近接方策最適化(PPO)などの手法が、ここでも基盤になっている。
現実で強化学習を回す最大の障害は、試行回数の多さと失敗の危険である。だからこそ、GPU上で数千の仮想環境を並列に走らせ、現実の数百倍の速度で経験を積ませるシミュレーション学習が要になる。実務では、まず人間の遠隔操作データを真似る模倣学習で方策の土台を作り、その上に強化学習で最適化を重ねる併用が定着しつつある。世界モデルが提供する「夢の中での試行」と、シミュレーターが提供する「並列の試行」が、現実での危険な失敗を肩代わりしている構図である。
センサーとアクチュエーター、そして計算基盤
物理AIは、計算・知覚・駆動という三つの物理装置の上に立つ。計算基盤では、エヌビディアがCES 2026で公表したVera Rubinプラットフォームが次世代の中心に座る。Arm系の新CPU「Vera」と新GPU「Rubin」を組み合わせ、ラック構成「NVL72」は72基のRubin(GPUダイ144個)と36基のVeraを束ねる。
- Rubin GPU: トランジスタ3,360億個(Blackwell比1.6倍)、HBM4を最大288GB搭載、メモリ帯域22TB/秒(同2.8倍)。
- NVL72ラック: 推論3.6エクサFLOPS、学習2.5エクサFLOPS、HBM4を20.7TB、帯域累計1.6PB/秒。
- 推論特化のNVL144 CPX: 8エクサFLOPS、高速メモリ100TB、帯域1.7PB/秒で、長文脈推論の前処理段に最適化。
これらは大規模学習・推論の側を担い、ロボット本体にはJetson Thor級の省電力エッジ計算機が積まれる。知覚側では、カメラに加え、光の往復時間で距離を測るLiDAR(飛行時間方式)、姿勢を測る慣性計測装置(IMU)、力とトルクを測る六軸センサー、そして指先の圧力分布を捉える触覚センサー(電子皮膚)が組み合わさる。触覚は、滑りや微妙な把持力を要する作業で「最後の1センチメートル」を埋める鍵とされ、視覚だけでは届かない接触情報を補う。駆動側では、波動歯車装置(ハーモニックドライブ)による高減速・高精度の電動関節が標準化しつつある。ボストン・ダイナミクスが2026年に量産するAtlasは56個の能動関節を備え、多くが360度回転して人間の可動域を超える。
規則からエンドツーエンド、そしてVLAへ ― 自動運転の三段転換
自動運転は、物理AIが最も早く「データの循環」と「事業の循環」を確立しうる分野である。価値の高い相互作用場面、継続的に集まるマルチモーダルな実世界データ、明確な収益化の道筋、そして量産可能な部品供給網がそろう。自動車メーカーの技術方式は、人手で規則を書き込む「規則駆動型」から、知覚から制御までを一つの神経回路網で貫く「エンドツーエンドAI」を経て、いまや視覚・言語・行動を統合する「VLA」へと移っている。
エヌビディアがCES 2026で公開したAlpamayo 1(オープンソース)は、この転換の到達点を示す。Cosmosを土台にした100億パラメータの推論型VLAで、複数カメラの映像・ナビ情報・運転文脈を入力に、軌道と「因果連鎖(Chain-of-Causation)」の推論過程を同時に出力する。過去に経験のない交差点の信号故障のような極端な例外事例(エッジケース)を、人間のように推論で切り抜けることを狙う。1,700時間超の実運転データとAlpaSimシミュレーション基盤が公開され、Cosmosが生成する合成エッジケースと実データを組み合わせて検証できる。自動運転の積年の課題だった「データ収集の高コストとラベル付けの困難」を、高精度の合成データが緩和する構図である。理想汽車の自動運転責任者がGTC 2026で「自動運転は物理AIの出発点にすぎず、同一のVLAを土台にすれば車両もロボットも制御できる」と述べたように、車と身体の制御が同じ基盤へ収束しつつある点が、この分野の射程を広げている。
試作から実機配備へ ― ヒューマノイドとデータの好循環
ヒューマノイドは、試作機による検証から小規模・大規模の実機配備へ移行しつつある。CES 2026で公表されたグーグル・ディープマインドとボストン・ダイナミクスの提携は、Gemini Robotics基盤モデルを新型Atlasに統合し、自動車を皮切りに産業作業をこなすことを目標に掲げた。ディープマインドのGeminiによる強化で、Atlasは視覚と動作が連動した推論を獲得し、技術者が歩き方や掴み方を一行ずつ書き込む必要がなくなる。母体である現代自動車の工場にロボット・メタプラント応用センター(RMAC)が2026年に開設され、工場データがAtlasのもとへ還流する設計だ。
競争の決め手は、この「データのクローズドループ」を回せるかにある。フィギュアは自社工場「BotQ」と最新の制御モデルを足がかりに「生産規模そのものがデータ蓄積を生む」経路を築き、テスラは運転支援(FSD)で培ったデータ収集体制と自社のAI計算基盤(Cortex)の演算力をヒューマノイドのOptimusへ転用する。中国の宇樹科技(Unitree)やアジボット、ギャラクシーボットも実機データと合成データの蓄積を急ぐ。配備台数が増えるほど「データ増加→モデル更新→能力向上→適用拡大」という好循環(フライホイール)が回り始める。
製造現場では、デジタルツインが先行する。工場や生産ラインの仮想的な双子を作り、温度や距離などの現場データを同期させ、AIを仮想環境で先に訓練してから実機へ移す。立ち上げ期間と試行コストを圧縮できるため、BMWやメルセデス・ベンツが組立ライン設計の最適化に、フォックスコンやペガトロンがマニピュレータやヒューマノイドの仮想検証に採用している。物理AIを積んだ溶接ロボットがミリ以下の精度で両手協調作業をこなすといった事例も現れ、固定的な工場自動化(FA)から、環境変化に動的に応じる柔軟生産への転換が進む。物理AIの学習データには、計算機支援工学(CAE)のソルバーによる物理的に矛盾しない合成データが不可欠で、実機1台の裏で数千時間規模のCAEシミュレーションが回るという、産業用ソフトウェアへの新たな需要も生まれている。
手術室と実験室へ広がる身体性
物理AIの応用は、製造と自動運転の外へも染み出している。手術支援では、生体組織の張力や縫合の強さ、器具の微細な変形を計算し、制御指令をリアルタイムに微調整してミリ単位の操作を実現する方向が探られている。心臓の冠動脈バイパスのように、血流と組織の弾性を読みながら血管を最適な圧力で吻合する用途で、触覚と物理モデリングの融合が効く。健康管理では、アップルがiPhoneやApple Watchから得るデータを端末側で処理し、異常検知から受診勧奨までを担う健康エージェントを構想しており、「病気になってからの治療」から「予防」への重心移動と、データを手元で処理する個人情報保護を両立させようとしている。
科学研究そのものを自動化する「AI for Science」も初期実装に入った。物理AIが「仮説の設定→実験の実施→結果の分析→手順の更新」という循環を自動化し、自動実験プラットフォームを高速で回すことで、新材料・新薬・複雑な製造プロセスの探索を加速する。屋内空間の管理では、固定カメラと画像認識を組み合わせ、工場や物流倉庫における人・車両・ロボットの動きを追跡し、動的な経路最適化で安全と効率を高める応用が広がっている。
誰が「土台」を握るか ― エヌビディアの垂直統合と各陣営
競争環境は、巨大企業の牽引と、その周囲のエコシステム協調という形をとる。エヌビディアは基盤モデル層で突出した位置にある。ロボット全身制御のGR00T、シミュレーションのIsaac/Omniverse、世界モデルのCosmos、推論型VLA、学習・推論用チップ、そして開発基盤CUDA-Xまでを自社で垂直統合し、物理AIを手がける企業の多くが、そのいずれかに依存する。フアンが追うのは、ロボットの「アンドロイド」——誰もが乗る共通プラットフォーマー——の地位である。GTC 2026では、ケイデンス、ダッソー・システムズ、PTC、シーメンス、シノプシスという産業用ソフトウェアの主要5社との連携も公表し、CUDA-XとOmniverseを既存の設計・製造ソフトのエコシステムへ流し込んだ。
対するグーグル・ディープマインドは、相互作用可能な世界モデルGenie、ロボット向け基盤Gemini Robotics、そしてボストン・ダイナミクスとの提携を通じて、モデル側の強みで市場へ食い込む。フィギュア、フィジカル・インテリジェンス(Pi)、テスラも独自の基盤モデルを開発する。中国勢は様相が異なり、ヒューマノイドメーカー自身が基盤モデルを内製し、大手IT企業はインフラ支援に回る。国内の大手言語モデル勢の計算資源が汎用人工知能(AGI)路線に向かい、ロボットのハードウェアへの投資に慎重な一方、資金力を持つヒューマノイド企業が自前のモデル開発チームを抱えられるためだ。シミュレーション基盤では国産勢が強く、アジボットのGenieSim 3.0がCES 2026でオープンソース化されてIsaac Lab+Cosmosに対抗し、索辰科技のKaiwuが生成型物理AIとフォトリアルなレンダリングで多物理シミュレーションを担い、51World傘下の51Simが中国のエンドツーエンド自動運転シミュレーション市場で過半を占める。
国内の技術プレーヤーを技術の側面から見ると、それぞれの参入障壁が見えてくる。51Worldは3次元グラフィックス・シミュレーション・人工知能を束ね、データ基盤からエンジン、プラットフォーム、業界アプリまでを一貫して持つデジタルツインの先行企業である。索辰科技は計算流体力学や構造解析のソルバーを長年蓄積し、その物理ソルバーの優位をドローンや低空経済の領域へ展開している。群核科技(ManyCore)は、1万台超の高性能プロセッサで構成する専用GPUクラスターを自社運用し、2Kの高精細画像1枚を平均1.2秒で描画(業界平均は2秒超)、1日平均12万件の計算処理をこなす。5億件超の3次元空間データと4億4,000万件超の3次元モデルを土台に独自の空間大規模モデルを構築し、設計者という人間向けの空間編集ツールから、ロボットやAI向けの「空間知能」基盤へと事業の対象を広げている。
通信と計算をめぐる陣営図 ― Starlink、ソフトバンク、OpenAI対xAI
数十億の自律機械が現実で動く時代には、それらを結ぶ通信網と、末端で推論を回すエッジ計算が物理AIの不可分の一部になる。ここでは技術と陣営の構図を整理する。
低軌道衛星による接続は、地上の携帯網と競合し始めた。スターリンクは2022年10月にアジアで最初に日本へ参入し、国内ではKDDIと組んで衛星から携帯端末へ直接電波を届ける「au Starlink Direct」を展開する。物理的な要点は高度にある。静止衛星が約3万6,000キロから通信するのに対し、低軌道衛星は約550キロで、往復遅延が一桁以上小さく、手のひらの端末へ直接届く電波設計(リンクバジェット)が成立する。これに対しNTTはスペースコンパスや成層圏プラットフォーム(HAPS)で、ソフトバンクはワンウェブ(低軌道の競合網)や独自のHAPSで別経路を組む。スターリンクの日本展開はKDDIを味方につける一方、NTTとソフトバンクとは「衛星から携帯へ直接」の層で正面から対峙する構図になる。
計算基盤と物理AIをめぐるソフトバンクの立ち位置は、二つの事実から読み取れる。第一に、孫正義氏はオープンエーアイ、オラクルと組んだ大規模データセンター建設計画(スターゲート)の中核に入り、傘下のArmは前述のとおりエヌビディアの新CPU「Vera」をはじめ、AI計算基盤のCPU設計資産を広く供給している。物理AIの演算層の根に、ソフトバンクのArm IPが横たわる。第二に、ソフトバンクは2017年から2020年にかけてボストン・ダイナミクスを保有し(現在は現代自動車傘下)、ヒューマノイドのPepperを世に出すなど、ロボティクスに長い関与を持つ。孫氏はサム・アルトマン氏のオープンエーアイ陣営に深く組み込まれており、一方のイーロン・マスク氏は2015年にオープンエーアイを共同創業しながら2018年に離脱、2024年に同社を提訴し、自らはxAIとメンフィスの大規模計算機「コロッサス」で対抗する。
この対立軸に孫氏を置けば、答えは構造から導かれる。孫氏はアルトマン氏側の最大級の建設パートナーであり、マスク氏のxAIとは計算基盤をめぐって反対側にいる。過去に孫氏とマスク氏の出資交渉が不発に終わった経緯もある。したがって、孫氏がマスク氏の企業へ改めて資本を投じる展開は、オープンエーアイ陣営との整合から見て起こりにくい——これは現時点の陣営図から読み取れる記者の観察である。マスク・アルトマンの対抗の中で、孫氏は中立の調停者ではなく、明確にアルトマン側の基盤建設者として位置している。
残る技術的な壁 ― sim-to-realの溝とデータの希少性
物理AIの社会実装を阻む壁は、宣伝文句よりも地味で根深い。第一に、シミュレーションと現実の乖離は領域ランダム化で緩和されたが消えてはいない。仮想で完璧でも、現実の摩擦・照明・センサー雑音の僅差で方策が崩れる危うさは残る。第二に、データの希少性である。言語モデルがインターネット規模のテキストで育つのに対し、ロボットの動作データは人手の遠隔操作でしか集まらず、モラベックの逆説が突きつけた「知覚運動の難しさ」がそのままデータの壁として立ちはだかる。Open X-Embodimentの機体横断学習やCosmosの合成データは、この壁を乗り越えるための賭けにほかならない。第三に、長期にわたる作業の信頼性、安全性、そして判断根拠の不透明さ(説明可能性)が、医療や公道といった失敗の許されない領域で実装の速度を律する。
この三つの壁を越えた先に見えるのが、現実を忠実に再現した仮想世界——いわゆるデジタルアース——の構築である。その価値は、一度作った都市の精細な3次元データが、交通計画にも、自動運転の学習にも、災害シミュレーションにも、都市運営にも使い回せる再利用性に宿る。「一度のモデリングで何度でも再利用する」という規模の効率を握るのは、デジタルツイン基盤と標準化された仮想データ供給に特化したプラットフォーム型の企業になる——金鉱掘りにスコップを売る側の役回りである。物理AIが、認識する知能から世界に触れる知能への移行であるならば、その勝敗は派手なヒューマノイドの動画ではなく、世界モデルの予測精度、VLAの汎化、シミュレーションと現実の溝をどれだけ詰められるかという、地味な技術指標の上で決まる。
主要な技術的裏付け(参照論文・発表)
本稿の技術記述は、以下の一次資料(査読論文・公式発表)に基づく。世界モデルの系譜はHa & Schmidhuber「World Models」(NeurIPS 2018)とHafnerらのDreamer系列(2019・DreamerV3 2023)、シミュレーション転移はTobinら「Domain Randomization」(IROS 2017)とオープンAIのDactyl(2019)、動作生成はChiら「Diffusion Policy」(RSS 2023)、機体横断データはOpen X-Embodiment / RT-X(arXiv:2310.08864)。基盤モデルはエヌビディアCosmos(arXiv:2501.03575、2,000万時間・約9,000兆トークン)、Isaac GR00T N1(arXiv:2503.14734、20億パラメータ二系統VLA)、フィジカル・インテリジェンスπ0(PaliGemma 3B+行動エキスパート、フローマッチング50Hz)、フィギュアHelix(2025年2月、上半身全制御)、グーグル・ディープマインドGenie 3(24fps/720p)。直近の製品発表はエヌビディアAlpamayo 1(CES 2026、100億パラメータ推論型VLA)、Vera Rubinプラットフォーム、ボストン・ダイナミクス×グーグル・ディープマインド(Gemini Robotics×Atlas、CES 2026)。